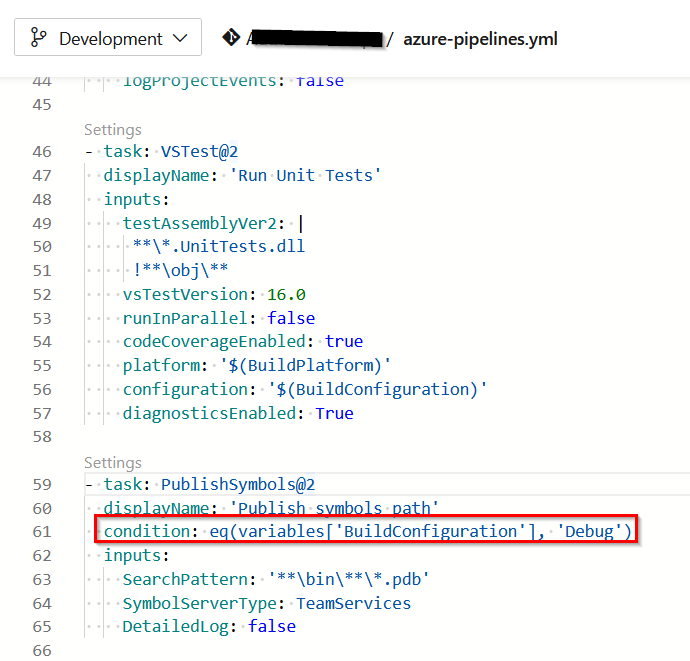
The current industry standard is having CI/CD pipelines defined as part of the application code so it can be managed in the version control system the same as any application code is managed. Of course Azure DevOps has build-in support for this with pipeline code defined in yaml files. In the past the main way to define CI/CD pipelines was using a web interface and saving the pipeline in Azure Devops itself. For a few years now this is called the “Classic” mode, where Infrastructure as Code (IaS) is now the modern mode. This is an example of a Azure Devops IaS pipeline defined in a yaml file:
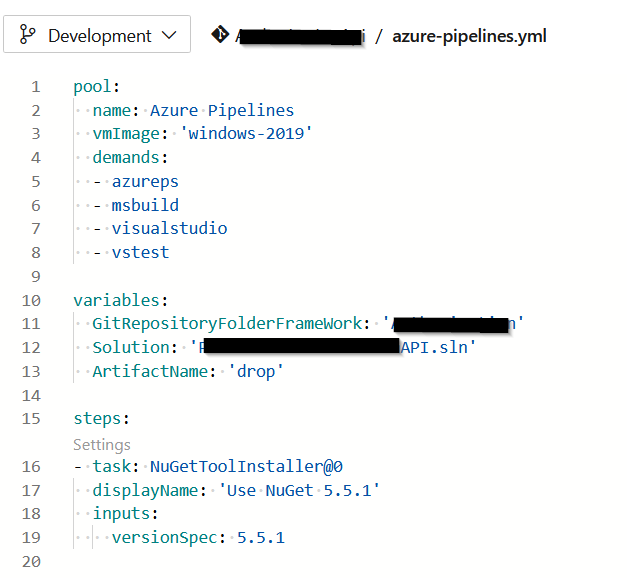
It is also a good practice to support the different CI scenario’s used for building the application. For example, the pipeline code can support the creation of a DEBUG build and a RELEASE build. This can be done by referring to pipeline variables that are specified as input parameters for the build script. The following syntax is used to refer to a variable: ‘$(variable-name)’. Variables can be defined for a pipeline in ADO, but can also be overwritten for specific run.
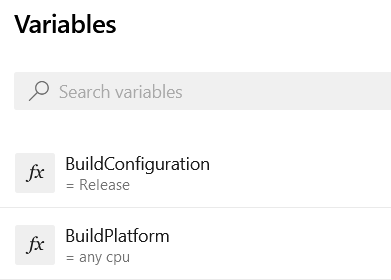
As you can see in the example yaml file above, ADO pipelines are a series of “steps”. The variables can be used as input for those steps to make the steps behave in a certain way, such as creating a DEBUG or a RELEASE build. Steps can also be skipped completely, by adding a run condition to the step to be skipped. Several internal functions, such as startsWith and eq can be used to check provided variables. I’ve used this functionality to skip the publishing of debug symbols on a release build: